Random_genesis

- Scientific worldbuilding
Constructing fictional places has always been one of the main goals in the general field of procedural generation.
However, in most cases, even the generation of entire worlds has just been a necessary step in the creation of some other product. The generation tends therefore to focus on a few aspects that are core to the final product, while many variables are left aside.
The idea is to try and create large territories, where many different variables are scientifcally taken into account: geology, geography, climate, ecology...
Possibly, through the application of some "Guns, Germs and Steel-like" mechanics it will be possible to simulate large scale interactions between humans and the environment, and among humans on a large scale.
The Great Flood (Mar 2018)
>Previous Update
The heightmaps produced tend to show inland depressions: areas where the height value goes below sea level, but are not connected to the ocean.
These areas will be treated as land rather than sea: they might be filled again by rivers, but for now need to be detected and flagged as dry ground.
An algorithm is therefore required to recognise different unconnected bodies of water. As a general definition, every water tile connected to the edge of the map will be considered "ocean", while every unconnected body of water will be flagged as "lake", and its water removed.
In turn this will allow to produce and store a more informative map data structure, where height and "terrain type" are independent and stored separately.
The most common solution to solve this kind of problem is a flood fill algorithm of some description.
There are many variations and many ways to implement each variation, in this case the need for efficiency is not super extreme, but it's better to have a reasonable implementation anyway.
Any kind of recursive algorithm is certainly excluded, due to the stack overhead involved.
Some implementations trade some time efficiency in order to keep the memory required constant. However in this case memory is likely not going to be a huge issue, since the maps are limited in size, and C# can handle a few thousand nodes easily.
To keep things simple, a queue/stack based algorithm should prove quick enough.
The choice between Breadth-first (BFS) and Depth-first (DFS) is trivial: although they have the same asymptotic complexity, DFS requires much less memory.
The resulting, well known, algorithm will have a complexity in time linear in the number of pixels to fill (for each pixels we check its four neighbours), and a space complexity proportional to the length of the longest path.
In this specific case, it is possible to exploit a-priori knoweledge about the problem at hand to speed things further: in fact, since we are flagging as "ocean" all the tiles that are connected to the edge of the map, we can flag a good part of them with a linear scan of the matrix. Starting from one edge and moving towards the other, it is safe to flag as ocean every tile until land is reached, at which point the loop starts from the opposite edge. This can be done along both axes, to fill parts of the map without the need for any flood fill.
It is immediate to say that going from one edge to the opposite no tiles will ever be checked twice, meaning that repeating it for both axes will flood a certain percentage of the map (it depends on the geometry and alignment of landmasses, difficult to estimate) at the cost of 1-2 checks per tile.
This is therefore 50% to 75% faster than using flood fill (on the tiles that directly "see" any edge), while requiring zero memory. It is also quick and extremely easy to implement.
The heightmap: some bodies of water are not connected to the main ocean and should be detected as such. A large one is visible on the bottom-left.

The first scan along the x axis: each column is checked from the top and from the bottom.
Landmasses are highlighted in red for clarity.

The second scan along the y axis, as if it ran without the first.

The second actually runs straight on top of the first. The result is a partitioning of the remaining tiles in smaller areas.
Number and size of the remaining uncolored areas depend on the distribution of landmasses.

Then a flood fill is ran on each uncolored area: if the flood touches any ocean before terminating the tiles it covers are flagged as "ocean", otherwise as "lake" (in green).
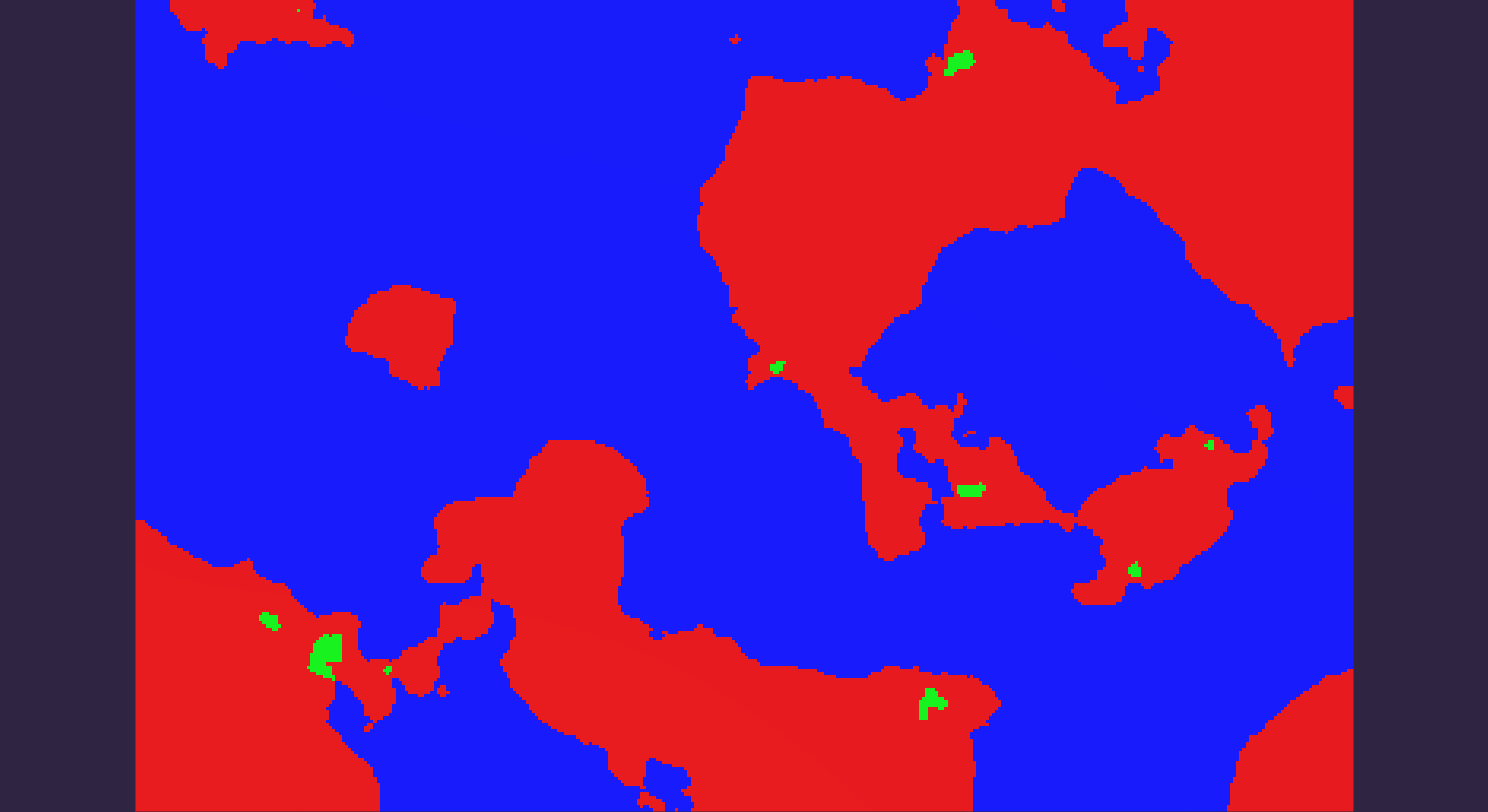
As an added bonus, having to run multiple flood fills on small unconnected ares uses way less memory than on a big one, although on this scale this is likely to be nearly irrelevant.
Moreover, scanning a matrix linearly is (in theory) faster than random-accessing its values like you do during a flood fill, because the relevant portion of memory can be more easily predicted.
The impact of this (if any) really depends on how C# does things on the base level, on the OS and the hardware. This would be extremely relevant if the matrix was memory-mapped on a disk, and it might have no impact at all in this case.